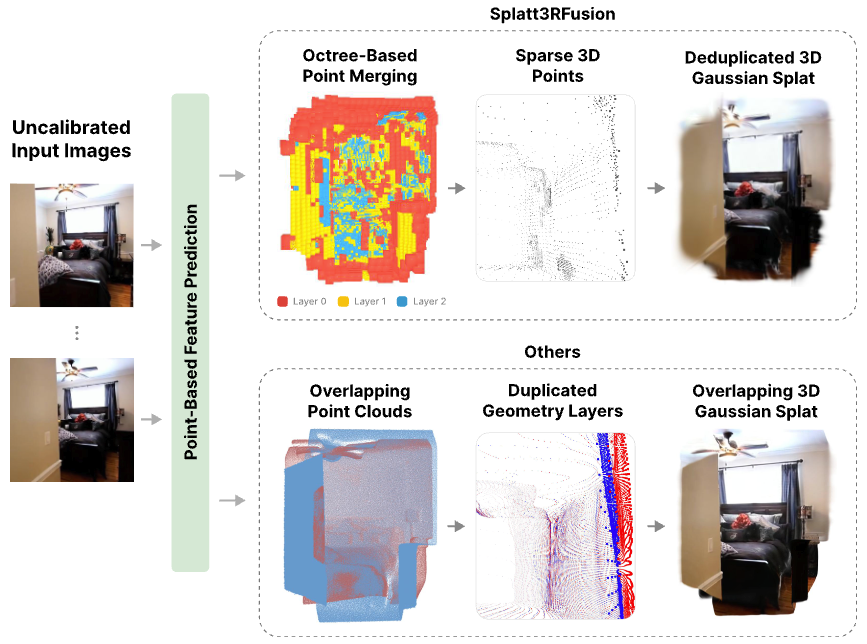
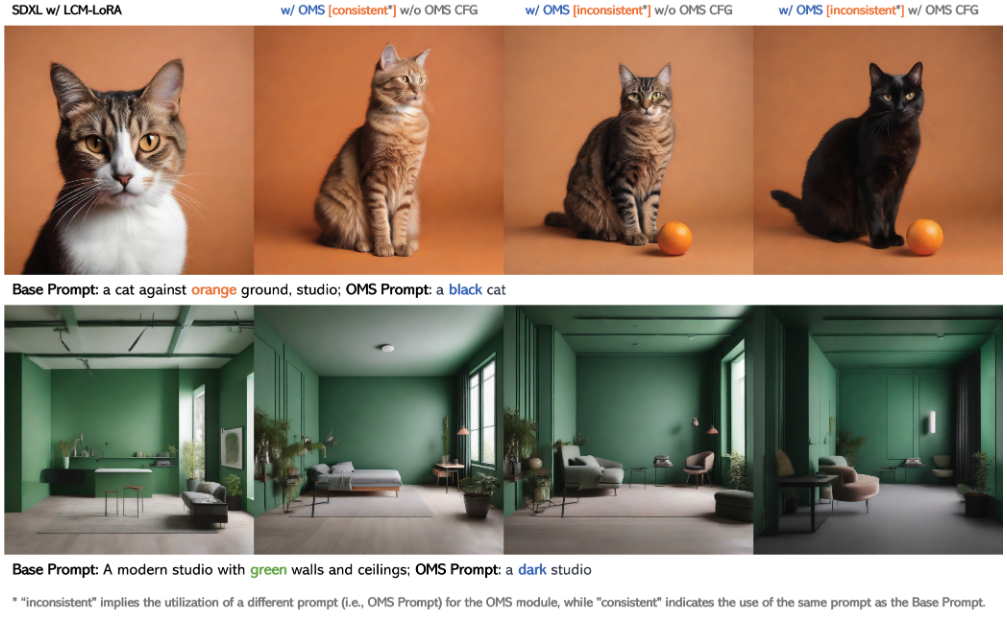
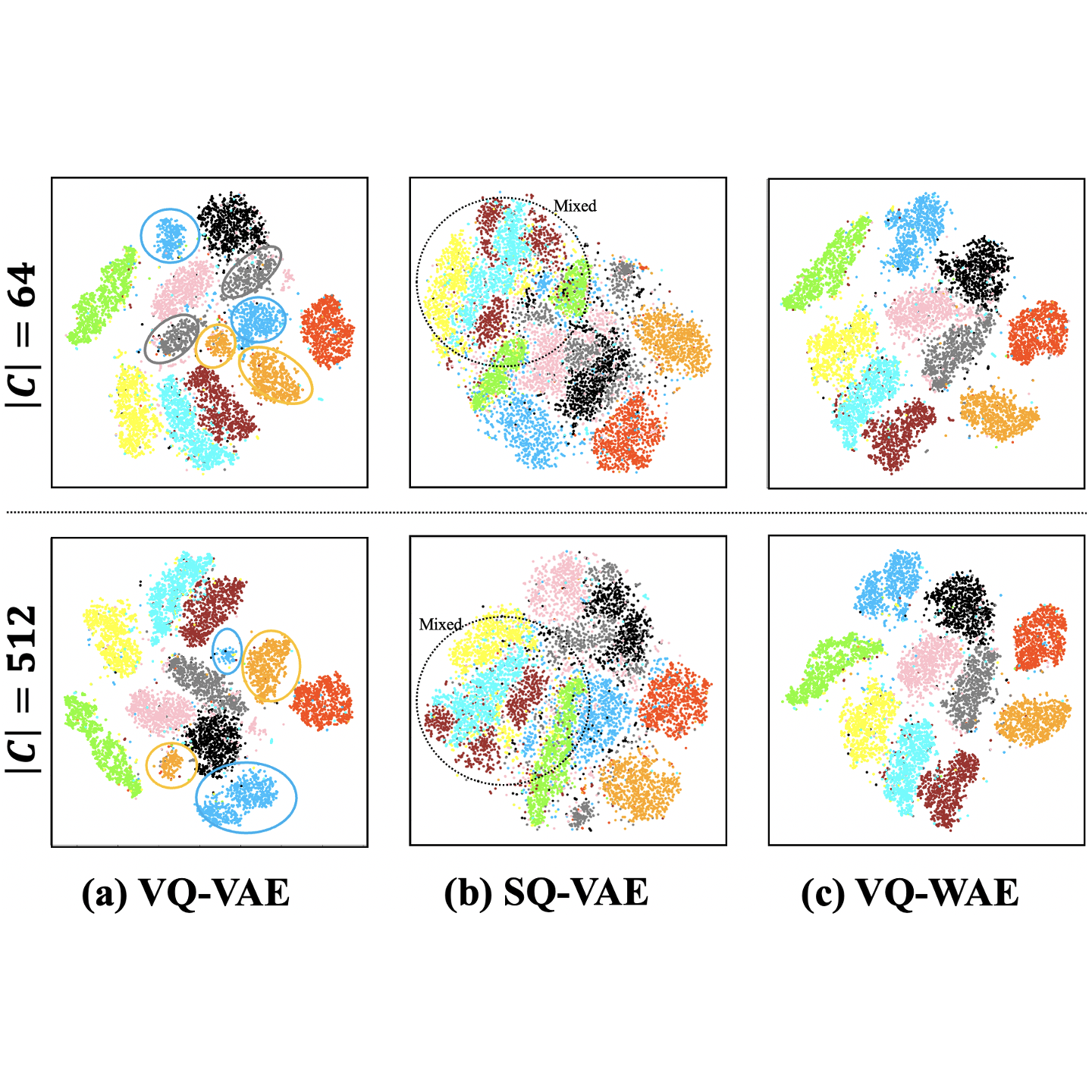
Syn4D: A Multiview Synthetic 4D Dataset
ECCV, 2026
Zeren Jiang, Yushi Lan, Yihang Luo, Yufan Deng, Zihang Lai, Edgar Sucar, Christian Rupprecht, Iro Laina, Diane Larlus, Chuanxia Zheng, Andrea Vedaldi
A large-scale synthetic multiview 4D dataset with dense geometry, tracking, camera motion, and human pose annotations.